Claude Opus 4.7: 87.6% SWE-bench and a Hidden Cost Increase
Anthropic's Opus 4.7 jumps to 87.6% on SWE-bench Verified, adds 3.3x vision resolution and a new xhigh effort level — but an updated tokenizer means the same input now costs up to 35% more.
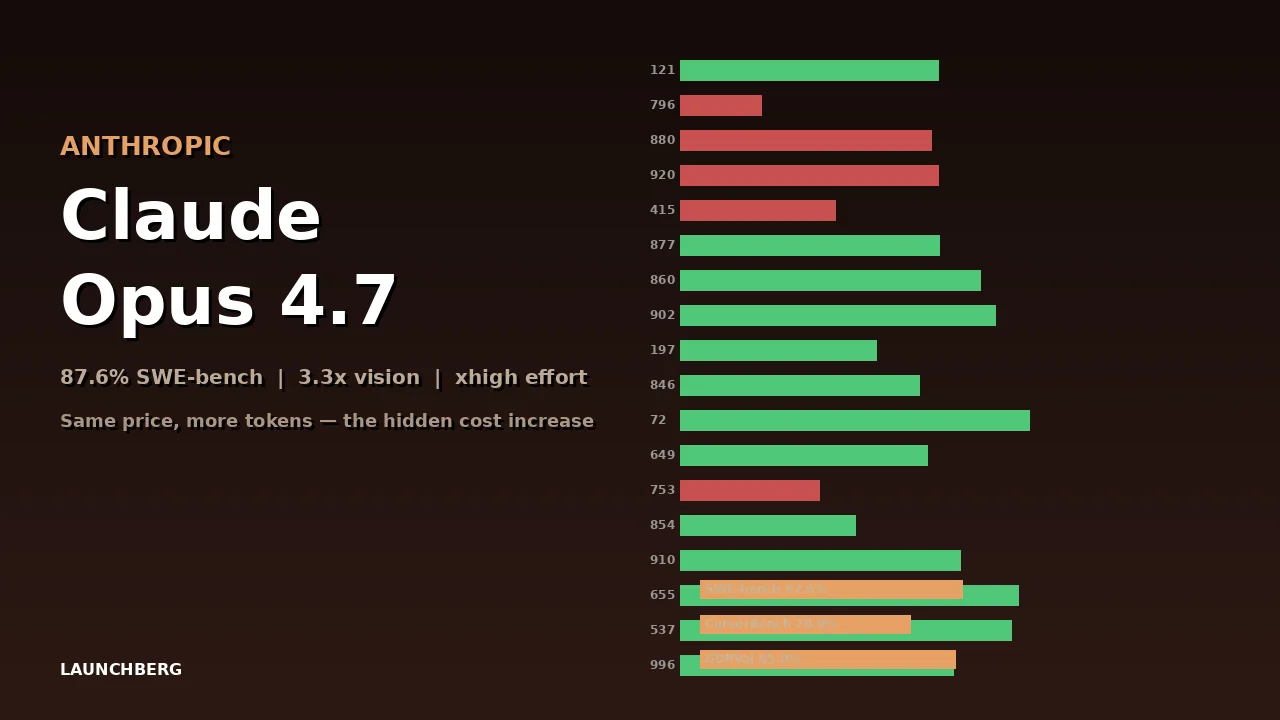
The pricing page says $5 per million input tokens — unchanged from Opus 4.6. But read the fine print and you’ll find the catch: Opus 4.7 ships with an updated tokenizer that maps the same text to 1.0–1.35x more tokens. Your bill goes up without the price going up. It’s the kind of move that technically isn’t a price increase while functionally being a price increase.
That said, what you’re paying for is substantially better.
The Coding Jump
SWE-bench Verified — the curated set of 500 human-validated GitHub issues — goes from 80.8% on Opus 4.6 to 87.6% on Opus 4.7. That’s a 6.8-point improvement in one version bump. SWE-bench Pro, the harder subset, jumps from 53.4% to 64.3%. CursorBench climbs 12 points, from 58% to 70%.
These aren’t incremental gains. A 12-point jump on CursorBench means Cursor Composer 2 — which just launched at 61.3% on that same benchmark — is already behind Opus 4.7 on the metric designed to measure AI coding inside Cursor’s own editor.
On GDPVal-AA, an Elo-based benchmark for knowledge work, Opus 4.7 scores 1,753. GPT-5.4 sits at 1,674. Gemini 3.1 Pro lands at 1,314. For the first time, Claude holds the top position on a general knowledge work benchmark — not just coding.
xhigh and Task Budgets
Opus 4.7 introduces a new effort level called “xhigh,” slotted between the existing high and max. It’s tuned for coding and agentic workloads where you want deeper reasoning without committing to the full latency hit of max effort.
Task budgets pair with this. You can now cap token spend per job — tell the model “think hard, but don’t burn more than N tokens.” This is activated through the task-budgets-2026-03-13 beta header with an output_config.task_budget parameter. For teams running autonomous agents, this is the difference between “the agent ran for 45 minutes and used $12” and “the agent ran for 45 minutes and used $200.”
3.3x Vision Resolution
Opus 4.7 accepts images up to 2,576 pixels on the long edge — roughly 3.75 megapixels, versus 1.15 megapixels on Opus 4.6. On a visual navigation benchmark (no tools), that resolution bump pushes accuracy from 57.7% to 79.5%.
The practical impact: screenshots, documents, and diagrams that were too detailed for Opus 4.6 now resolve clearly. If you’ve been downscaling images before feeding them to Claude, you can stop.
The Safety Layer
Opus 4.7 is the first Claude model with automated detection and blocking for prohibited cybersecurity uses. Anthropic hasn’t detailed the mechanism, but the implication is that the model now actively refuses certain categories of security-related requests that previous versions handled ambiguously.
What This Means for Developers
The 1M token context window and 128K max output stay the same. The model string is claude-opus-4-7. It’s available on claude.ai, the API, Bedrock, Vertex AI, and Microsoft Foundry.
If you’re building coding agents on Claude, the xhigh effort level plus task budgets is the real upgrade — better reasoning with predictable costs. If you’re doing vision work, the 3.3x resolution increase is transformative. And if you’re watching your API bills, check your token counts after migration. That tokenizer change is silent but not small.